

Les tests statistiques permettent essentiellement d’évaluer les répartitions obtenues pour savoir si elles sont dues au hasard ou si elles recèlent des informations intéressantes.
Fisher, Kendall, Student, Pearson… Autant de noms familiers à tous ceux qui ont manipulé un jour ou l’autre des statistiques et des probabilités.
Les tests d’hypothèse associés à ces noms de mathématiciens ou statisticiens sont aujourd’hui très largement utilisés dans de nombreux domaines de recherche, pour évaluer la significativité des observations recueillies.
Dans l’univers des études marketing, seuls certains tests comme celui du Khi 2 sont fréquemment utilisés. Comme nous allons le voir, les autres tests disponibles peuvent également être très utiles au chargé d’études.
Principes généraux
Objectifs
Il existe de très nombreux tests qui permettent d’évaluer des aspects différents de significativité. Les objectifs principaux auxquels peuvent répondre les tests statistiques sont :
- l’évaluation de la représentativité des répartitions observées par
rapport aux valeurs connues pour l’ensemble de la population,
- la mesure de la significativité de la différence constatée sur les
observations de deux groupes d’individus ou d’un même groupe pour deux
variables observées,
- l’existence et l’intensité d’une liaison entre deux variables.
Fonctionnement
Les tests statistiques fonctionnent tous sur le même principe qui consiste à énoncer une hypothèse sur la population mère puis à vérifier, sur les observations constatées, si celles-ci sont vraisemblables dans le cadre de cette hypothèse.
Autrement dit, on cherche à estimer la probabilité de tirage au sort dans la population-mère, d’un échantillon ayant les caractéristiques observées. Si cette probabilité est minime, on rejette l’hypothèse énoncée ; dans le cas contraire, celle-ci peut être adoptée, au moins provisoirement, dans l’attente de validations complémentaires.
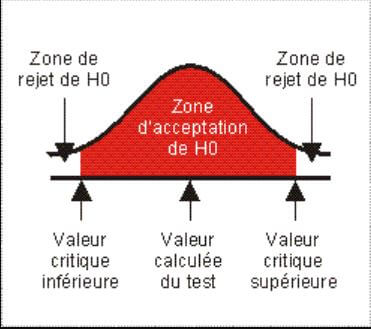
L’hypothèse à tester est appelée H0 ou hypothèse nulle. Elle s’accompagne impérativement de son hypothèse alternative appelée H1.
Le test s’attachera à valider ou à rejeter H0 (et par conséquent a tirer la conclusion inverse pour H1).
Si le résultat du test amène à accepter l’hypothèse nulle H0, le chargé d’études en déduit qu’il ne peut rien conclure à partir des observations concernées, la probabilité que la répartition soit dûe au hasard étant élevée.
En revanche, le rejet de H0 signifie que la répartition des réponses récèle des informations particulières qui ne semblent pas être dûes au hasard et qu’il convient d’approfondir.
Mode d’utilisation
La mise en oeuvre d’un test statistique se déroule généralement en 5 étapes :
- Formulation de l’hypothèse nulle H0 et de son hypothèse alternative
H1 : ces hypothèses sont toujours formulées par rapport à la population
globale, alors que le test portera sur les observations effectuées dans
le cadre de l’échantillon.
Exemple : Par rapport à l’année dernière où nos clients avaient
donné une note de 8,7 sur 10 à notre magasin, la note donnée cette
année par 100 clients que nous avons interrogés et qui se situe à
8,5 sur 10 n’est pas signifcativement inférieure.
- Détermination du seuil de signification du test (appelé alpha et
décrit plus loin).
Exemple : nous acceptons un risque d’erreur de 5%.
- Dans le cadre des tests paramétriques (définition plus loin),
détermination de la loi de probabilité qui correspond à la
population-mère.
Exemple : si on interrogeait tous nos clients potentiels, les notes
données se répartiraient selon une distribution normale ayant un
écart-type de 1.
- Calcul du seuil de rejet de H0 pour déterminer la région de rejet
et la région d’acceptation de H0 (et inversement de H1).
Exemple : Pour un risque de 5%, la loi normale donne une valeur
critique de -0,1645. Si la valeur de notre test est supérieure à ce
seuil, notre hypothèse H0 est vérifiée : la note de cette année
n’est pas significativement inférieure.
- Décision de rejet ou d’acceptation de l’hypothèse H0.
Exemple : La comparaison de la différence entre 8,5 et 8,7, qui est
de -0,2 étant supérieure à la valeur critique, nous devons rejeter
l’hypothèse H0. Nous devons donc estimer que la note donnée cette
année est significativement inférieure à celle de l’année
dernière.
Test unilatéral, ou bilatéral
Lorsque l’hypothèse nulle consiste à tester l’égalité de la valeur du test avec une valeur donnée, le test est bilatéral. En effet, le rejet de l’hypothèse est décidé si la valeur du test est significativement différente, qu’elle soit inférieure (zone de rejet de gauche) ou supérieure (zone de rejet de droite).
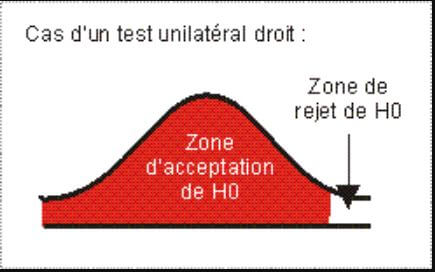
Le test est dit unilatéral lorsque l’hypothèse nulle évalue si une valeur est supérieure ou égale à la valeur de test (unilatéral gauche) ou inférieure ou égale à cette valeur (unilatéral droit).
Le test donné en exemple ci-dessus est donc un test unilatéral droit.
Tests paramétriques et non paramétriques
On distingue deux grandes catégories de tests : les tests paramétriques et les tests non paramétriques.
Les premiers exigent que l’on spécifie la forme de la distribution de la population-mère étudiée. Il peut s’agir, par exemple, d’une distribution suivant la loi normale, ce qui est le cas général lorsque l’on a affaire à de grands échantillons. En général, ces tests ne peuvent s’appliquer qu’aux variables numériques.
Les tests non paramétriques s’appliquent quant à eux, à la fois aux variables numériques et qualitatives. Ces tests ne font pas référence à une répartition particulière de la population-mère. Ils peuvent donc s’appliquer à des petits échantillons.
S’ils sont théoriquement moins puissants que les tests paramétriques, on peut quand même considérer que les tests non paramétriques sont plus adaptés aux problématiques d’enquêtes. Des études ont d’ailleurs prouvé que leur exactitude sur des grands échantillons n’est que légèrement inférieure à celle des tests paramétriques, alors qu’ils sont infiniment plus exacts sur des petits échantillons.
Erreurs-types
La conclusion retenue (rejet ou non de l’hypothèse H0) est établie avec une certaine probabilité d’erreur.
Lorsque le test conduit à rejeter l’hypothèse nulle, l’erreur éventuelle, dans le cas où cette hypothèse serait en réalité vraie, est appelée “Erreur de type 1” ou “Erreur alpha”.
Dans l’exemple décrit plus haut, l’erreur alpha était donc fixée à 5%.
Lorsqu’au contraire, le test nous indique qu’il ne faut pas rejeter l’hypothèse nulle, l’erreur éventuelle, au cas où cette hypothèse serait en réalité fausse, est appelée “Erreur de type 2” ou “Erreur Bêta”.
Ces indicateurs sont interdépendants : quand l’erreur alpha est réduite, l’erreur bêta augmente. Cela signifie que le choix du seuil alpha pour le test à effectuer doit se faire en fonction du coût économique de l’une ou l’autre mauvaise décision.
Exemple : Avant de lancer un nouveau packaging, une entreprise effectue un test pour vérifier qu’il plaît plus à ses clients que l’ancien.
Si l’hypothèse est vérifiée alors qu’elle est fausse, l’entreprise va remplacer l’ancien packaging qui plaît plus par un nouveau moins attirant. Elle va y perdre de l’argent et des clients.
En revanche, si le test lui indique que le nouveau packaging est moins attirant alors qu’il l’est plus, elle va perdre une opportunité en ne le lançant pas.
La comparaison des coûts de ces deux erreurs permet de fixer les seuils de manière optimale.
Notons que les indicateurs alpha et bêta permettent de formaliser un niveau de sécurité pour le résultat obtenu (1 – alpha) et un paramètre indiquant la puissance du test (1 – bêta).
Tests sur une variable
La production d’un tableau de résultats sur une question peut s’accompagner d’indicateurs statistiques de significativité. Le choix du test applicable dépend du type de la variable et de l’objectif poursuivi.
Tests d’adéquation
En présence d’un tableau de résultats pour une variable qualitative, le chargé d’études peut utiliser des tests non paramétriques destinés à comparer la répartition obtenue pour les différentes réponses avec une répartition connue (par exemple, celle de la population mère) ou une répartition théorique, issue d’une loi statistique (ex : loi normale).
Les deux tests d’adéquation les plus utilisés dans ce cas sont le test d’ajustement du Khi2 et le test de Kolmogorov-Smirnov. Ces tests permettent de répondre à des questions du type :
- Je connais la répartition de ma population selon les CSP. Mon
échantillon est-il représentatif de cette population sur ce critère ?
- Nous avons défini un plan de charge nous permettant d’ouvrir nos
caisses en fonction de la fréquentation de notre magasin. Ce modèle
est-il validé par nos observations sur un échantillon de jours et
d’heures donné ?
- Nous fabriquons des chaussures pour femmes. Peut-on considérer,
après avoir interrogé 200 clientes potentielles choisies au hasard que
les tailles de chausse suivent une loi normale ?
Ces tests calculent, à partir des écarts entre les valeurs réelles et les valeurs théoriques, une valeur que l’on compare à un seuil critique dans la table statistique correspondante.
Tests de conformité à un standard
Ces tests, très proches des tests d’adéquation évoqués ci-dessus, ont pour objectif de comparer une moyenne ou une proportion à une valeur particulière (comme dans notre exemple du début). Ainsi, le test de comparaison de la moyenne s’applique sur une variable numérique et permet de comparer la moyenne de la série à une valeur donnée. Notons qu’il n’est utilisable que pour des échantillons supérieurs à 30 individus.
Pour apporter une nouvelle illustration de l’utilité de ce test, prenons l’exemple d’un magazine qui affirme, pour vendre ses pages de publicité, que chacun de ses exemplaires vendus est lu en moyenne par 3,7 lecteurs. La comparaison de la moyenne permet, à partir d’un échantillon aléatoire d’acheteurs interrogés, d’évaluer la véracité de cette affirmation. Le test ne consiste pas seulement à comparer la moyenne obtenue, par exemple 3,2, avec la moyenne annoncée, mais à estimer la probabilité de tomber sur un échantillon ayant une moyenne qui s’écarte ainsi de 0,5 points ou plus de la vraie moyenne de 3,7. Si cette probabilité est importante, nous pouvons accepter la moyenne annoncée. En revanche, si elle est minime, on est en droit de rejeter l’affirmation.
Le test de comparaison d’une proportion fonctionne de la même manière, mais sur des variables qualitatives. Il permet de comparer le pourcentage de réponses obtenues à une modalité, à un pourcentage donné. Ainsi, si un directeur d’antenne s’est fixé un seuil d’au moins 25% d’auditeurs pour conserver une émission, et qu’il obtient, suite à une enquête la valeur de 22,5% d’auditeurs, le test de comparaison de la proportion obtenue avec le seuil visé peut l’aider à prendre une décision en minimisant les risques de se tromper.
Tests sur deux variables
Tests paramétriques de comparaisons d’échantillons
Ces tests permettent de comparer des résultats obtenus pour une variable, sur deux groupes d’observations, en vue de déterminer si ces résultats sont significativement différents d’un groupe à l’autre. Il peut s’agir, par exemple, d’un test de deux packagings ou de deux messages publicitaires, en vue d’évaluer la version la plus appréciée par les personnes interrogées.
Les tests paramétriques de comparaison les plus fréquents sont les tests de différence entre deux moyennes ou entre deux pourcentages.
Le premier s’applique sur des variables numériques. Il peut porter sur des échantillons indépendants ou appariés. A titre d’exemple, si on fait goûter une boisson à un groupe de femmes et à un groupe d’hommes pour voir s’il y a une différence d’appréciation selon le sexe, on réalise là un test sur des échantillons indépendants. En revanche, si on fait goûter deux boissons différentes à un même groupe d’individus, pour voir s’il y a une préférence significative pour l’une des deux, il s’agit d’une mesure sur des échantillons appariés.
Dans le premier cas, le test compare la moyenne pour le 1er et pour le 2ème groupe puis cherche à évaluer si cette différence est significativement différente de 0. Si tel est le cas, on peut considérer que les hommes n’apprécient pas la boisson de la même manière que les femmes. Pour savoir quel groupe l’apprécie le plus, il n’est pas forcément besoin de choisir que le test se fasse de manière unilatérale puisqu’il suffit de jeter un coup d’oeil sur les moyennes.
Dans le deuxième cas, le test consiste à calculer les différences entre les 2 notes données par chaque individu aux produits testés. Ensuite le test calcule la moyenne de ces différences puis essaie de voir si cette moyenne est significativement différente de 0. Si tel est le cas, on peut conclure que les produits sont notés de manière différente. Là aussi, l’appréciation du meilleur produit peut se faire par l’examen de la moyenne de chacun des deux ou alors, en demandant au départ un test unilatéral.
Le test de comparaison de deux pourcentages est également extrêmement utile pour évaluer la différence entre deux échantillons pour une modalité de réponse donnée (ou un regroupement de modalités). Ainsi, une enseigne de distribution peut comparer la proportion de clients satisfaits dans deux de ses magasins pour savoir si cette différence est significative.
Tests non paramétriques de comparaisons d’échantillons
Ces tests ont les mêmes objectifs que leurs homologues paramétriques, en étant applicables dans le cas général.
Le test U de Mann-Whitney s’apparente au test de comparaison des moyennes sur deux échantillons indépendants. Comme ce dernier, il s’applique essentiellement sur une variable numérique (ou qualitative ordinale).
Le test des rangs signés de Wilcoxon s’apparente également au test de comparaison des moyennes mais, cette fois, sur des échantillons appariés. Là aussi, les deux variables à tester doivent être numériques (ou assimilées).
Ces tests effectuent des classements des réponses et font intervenir dans leurs calculs, le rang associé. Ainsi le test de Mann-Whitney commence par mettre ensemble les réponses des 2 groupes X et Y et à les classer. Le calcul porte ensuite sur le nombre de fois où un individu du groupe X précède un individu du groupe Y. La somme de ces éléments permet d’obtenir la valeur du test à comparer à la valeur critique dans la table de Mann-Whitney.
Il existe un autre test non paramétrique permettant de comparer plus de 2 échantillons et qui est en fait la généralisation du test de Mann-Whitney. Il s’agit du test de Kruskal-Wallis, mesure de l’association entre deux variables qualitatives. Le croisement de deux questions qualitatives produit un tableau que l’on désigne généralement par « tableau de contingence ».
Pour savoir si la distribution des réponses de ces deux variables est dûe au hasard ou si elle révèle une liaison entre elles, on utilise généralement le test du Khi2, qui est sans doute le test statistique le plus connu et le plus utilisé dans le domaine des études marketing.
En général, le khi2 est calculé pour un tableau croisé. Cependant certains outils comme Stat’Mania sont capables de l’appliquer en série à un grand nombre de combinaisons de variables prises 2 à 2, pour détecter automatiquement les couples de variables qui présentent les liaisons les plus significatives.
Mesure de l’association entre 2 variables numériques
Lorsque l’on cherche à déterminer si deux variables numériques sont liées, on parle de corrélation. Les trois tests de corrélation les plus utilisés sont ceux de Spearman, Kendall et Pearson. Les deux premiers sont des tests non-paramétriques que l’on peut également appliquer sur des variables qualitatives ordinales. Ces deux tests commencent par classer les valeurs observées pour chaque individu à chacune des deux variables. Ainsi, si on cherche à évaluer la corrélation entre l’âge et le revenu, la première étape du calcul évalue pour l’individu 1 puis 2, puis n, son classement en fonction de l’âge et celui en fonction du revenu.
Le test de Spearman se base sur la différence des rangs pour chaque individu, pour donner, à partir d’une formule particulière, la valeur du test (r de Spearman). Plus cette valeur est proche de 0 plus les 2 variables sont indépendantes. A l’inverse, plus il est proche de 1 plus elles sont corrélées.
Il est possible de tester la signification statistique de cette valeur obtenue, à l’aide de la formule suivante de comparaison, basée sur le t de Student :
t = r x racine(n-2) / racine(1-r²)
Cette valeur doit être comparée dans la table de Student, à la valeur t avec n-2 degrés de liberté. Ainsi, si on obtient une valeur r de 0,8 sur un échantillon de 30 personnes, le calcul ci-dessus nous donne la valeur 8,53. La valeur donnée dans la table de Student pour 28 degrés de liberté avec un seuil de 5% d’erreur est de 2,05. Cette valeur étant inférieure à notre t calculé, le taux de corrélation calculé est significatif. Toutes ces opérations sont, bien entendu, assurées de manière automatique par tous les logiciels modernes d’analyse de données (par exemple STAT’Mania dont vous trouverez un descriptif sur www.soft-concept.com).
Le test de Kendall part de la même manière que celui de Spearman. Mais une fois que les rangs sont calculés, le test classe l’une des deux variables sur ces rangs et s’intéresse au nombre de fois où la deuxième respecte le même ordre de classement. En final, le test fournit un coefficient de corrélation que l’on appelle le Tau de Kendall dont on peut également évaluer la significativité à l’aide d’un test complémentaire.
Contrairement aux deux tests ci-dessus, le test de corrélation de Pearson est un test paramétrique exigeant. Il ne s’applique que sur deux variables numériques qui, prises ensemble doivent suivre la loi normale (difficile à vérifier dans les études marketing). Ce test de corrélation fait appel à des calculs statistiques basés sur la covariance des deux variables et sur leurs variances. Là aussi, ces calculs aboutissent à la production d’un coefficient de corrélation entre 0 et 1, qui peut être également testé quant à sa significativité.










