

"Moins d'un" - l'apprentissage par injection peut apprendre à un modèle à identifier plus d'objets que le nombre d'exemples sur lesquels il est formé.
L'apprentissage machine nécessite généralement des tonnes d'exemples. Pour qu'un modèle d'IA reconnaisse un cheval, il faut lui montrer des milliers d'images de chevaux. C'est ce qui rend cette technologie si coûteuse en termes de calculs et très différente de l'apprentissage humain. Un enfant a souvent besoin de voir quelques exemples d'un objet, ou même un seul, avant de pouvoir le reconnaître pour la vie.
En fait, les enfants n'ont parfois pas besoin d'exemples pour identifier quelque chose. En montrant des photos d'un cheval et d'un rhinocéros, et en leur disant qu'une licorne est quelque chose entre les deux, ils peuvent reconnaître la créature mythique d'un livre d'images dès la première fois qu'ils la voient.
Un nouvel article de l'université de Waterloo, en Ontario, suggère que les modèles d'IA devraient également être capables de le faire - un processus que les chercheurs appellent l’apprentissage "moins d'un" – traduit de l’anglais LO-shot learning. En d'autres termes, un modèle d'IA devrait être capable de reconnaître avec précision plus d'objets que le nombre d'exemples sur lesquels il a été formé. Cela pourrait être une grosse affaire pour un domaine qui est devenu de plus en plus cher et inaccessible à mesure que les ensembles de données utilisés deviennent de plus en plus volumineux.
Comment fonctionne l'apprentissage "moins d'un" ?
Les chercheurs ont d'abord démontré cette idée en expérimentant avec le populaire ensemble de données de vision par ordinateur connu sous le nom de MNIST. Le MNIST, qui contient 60 000 images de formation de chiffres manuscrits de 0 à 9, est souvent utilisé pour tester de nouvelles idées dans ce domaine.
Dans un article précédent, les chercheurs du MIT avaient introduit une technique permettant de "distiller" des ensembles de données géants en minuscules, et comme preuve de concept, ils avaient réduit le MNIST à seulement 10 images. Les images n'ont pas été sélectionnées à partir de l'ensemble de données original, mais soigneusement conçues et optimisées pour contenir une quantité d'informations équivalente à celle de l'ensemble complet. En conséquence, lorsqu'il était formé exclusivement sur les 10 images, un modèle d'IA pouvait atteindre presque la même précision qu'un modèle formé sur toutes les images du MNIST.


Les chercheurs de Waterloo voulaient pousser plus loin le processus de distillation. S'il est possible de réduire 60 000 images à 10, pourquoi ne pas les comprimer en cinq ? L'astuce, ont-ils réalisé, consistait à créer des images qui mélangent plusieurs chiffres et à les intégrer dans un modèle d'IA avec des étiquettes hybrides, ou "douces". (Pensez à un cheval et un rhinocéros ayant les caractéristiques partielles d'une licorne).
"Si vous pensez au chiffre 3, il ressemble en quelque sorte au chiffre 8 mais rien à voir avec le chiffre 7", explique Ilia Sucholutsky, doctorant à Waterloo et auteur principal de l'article. "Les étiquettes souples tentent de saisir ces caractéristiques communes. Ainsi, au lieu de dire à la machine : "Cette image est le chiffre 3", nous disons : "Cette image est composée à 60% du chiffre 3, à 30% du chiffre 8 et à 10% du chiffre 0".
Les limites de l'apprentissage du LO-shot
Une fois que les chercheurs ont utilisé avec succès les étiquettes souples pour réaliser l'apprentissage LO-shot sur le MNIST, ils ont commencé à se demander jusqu'où cette idée pouvait réellement aller. Y a-t-il une limite au nombre de catégories qu'un modèle d'IA peut apprendre à identifier à partir d'un nombre infime d'exemples ?
Étonnamment, la réponse semble être non. Avec des étiquettes souples soigneusement conçues, même deux exemples pourraient théoriquement coder un nombre quelconque de catégories. "Avec deux points, vous pouvez séparer un millier de classes ou 10 000 classes ou un million de classes", dit Sucholutsky.
C'est ce que les chercheurs démontrent dans leur dernier article, à travers une exploration purement mathématique. Ils jouent le concept avec l'un des algorithmes d'apprentissage machine les plus simples, connu sous le nom de k-nearest neighbors (kNN), qui classifie les objets en utilisant une approche graphique.
Pour comprendre le fonctionnement de kNN, prenons l'exemple de la classification des fruits. Si vous voulez entraîner un modèle kNN pour comprendre la différence entre les pommes et les oranges, vous devez d'abord sélectionner les caractéristiques que vous voulez utiliser pour représenter chaque fruit. Vous pouvez choisir la couleur et le poids, ainsi pour chaque pomme et orange, vous alimentez le modèle kNN avec un point de données dont la couleur du fruit est la valeur x et le poids la valeur y. L'algorithme kNN trace ensuite tous les points de données sur un graphique en 2D et trace une ligne de démarcation au milieu entre les pommes et les oranges. À ce stade, la représentation graphique est divisée en deux classes, et l'algorithme peut maintenant décider si les nouveaux points de données représentent l'une ou l'autre en fonction du côté de la ligne où ils se trouvent.

Pour explorer l'apprentissage du LO-shot avec l'algorithme kNN, les chercheurs ont créé une série de minuscules ensembles de données synthétiques et ont soigneusement conçu leurs étiquettes souples. Ils ont ensuite laissé kNN tracer les lignes de délimitation qu'il voyait et ont constaté qu'il avait réussi à diviser le tracé en plus de classes que de points de données. Les chercheurs avaient également un degré élevé de contrôle sur l'emplacement des lignes de démarcation. En utilisant diverses modifications des étiquettes souples, ils ont pu faire en sorte que l'algorithme kNN dessine des motifs précis en forme de fleurs.
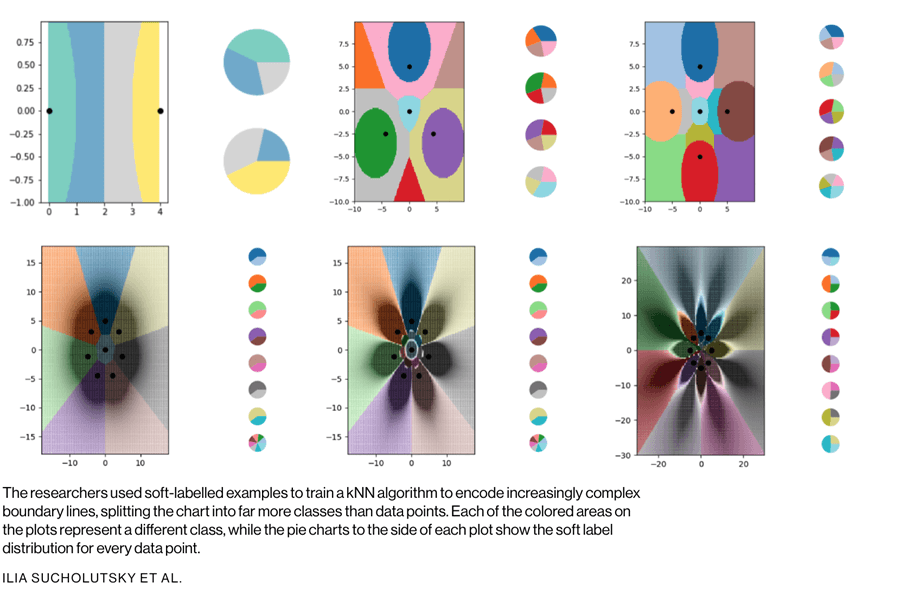
Bien sûr, ces explorations théoriques ont des limites. Alors que l'idée de l'apprentissage par le LO-shot devrait être transposée à des algorithmes plus complexes, la tâche d'ingénierie des exemples de marquage électronique devient beaucoup plus difficile. L'algorithme kNN est interprétable et visuel, ce qui permet à l'homme de concevoir les étiquettes ; les réseaux de neurones sont compliqués et impénétrables, ce qui signifie qu'il se peut que ce ne soit pas le cas. La distillation des données, qui fonctionne pour la conception d'exemples d'étiquetage souple pour les réseaux de neurones, présente également un inconvénient majeur : elle nécessite de commencer avec un ensemble de données géant afin de le réduire à quelque chose de plus efficace.
Sucholutsky dit qu'il travaille actuellement à trouver d'autres moyens de concevoir ces minuscules ensembles de données synthétiques, que ce soit à la main ou avec un autre algorithme. Malgré ces défis supplémentaires en matière de recherche, le document fournit les bases théoriques de l'apprentissage par le LO-shot. "La conclusion est que selon le type d'ensembles de données dont vous disposez, vous pouvez probablement obtenir des gains d'efficacité massifs", dit-il.
C'est ce qui intéresse le plus Tongzhou Wang, un étudiant en doctorat du MIT qui a dirigé les premières recherches sur la distillation des données. "Le document s'appuie sur un objectif vraiment nouveau et important : apprendre de puissants modèles à partir de petits ensembles de données", dit-il de la contribution de Sucholutsky.
Ryan Khurana, chercheur à l'Institut d'éthique de l'IA de Montréal, partage ce sentiment : le plus important est que l'apprentissage "en moins d'un coup" réduirait radicalement les besoins en données pour construire un modèle fonctionnel. Cela pourrait rendre l'IA plus accessible aux entreprises et aux industries qui ont jusqu'à présent été entravées par les exigences en matière de données du domaine. Cela pourrait également améliorer la confidentialité des données, car il faudrait extraire moins d'informations des individus pour former des modèles utiles.
Sucholutsky souligne que la recherche est encore précoce, mais il est enthousiaste. Chaque fois qu'il commence à présenter son article à ses collègues chercheurs, leur première réaction est de dire que l'idée est impossible, dit-il. Lorsqu'ils réalisent soudain qu'elle ne l'est pas, cela ouvre un tout nouveau monde.
Ce contenu est une traduction libre de l’article rédigé par
Karen Hao, et publié en anglais sur le site web de la revue MIT
Technology Review. Cliquez ici pour lire l’article d’origine.
Karen Hao rédige une lettre d'information hebdomadaire intitulée
The Algorithm, qui a été désignée comme l'une des meilleures lettres
d'information sur Internet en 2018 par The Webby Awards. Elle a
obtenu une licence en génie mécanique et une mineure en études
énergétiques au MIT.










