

Les scientifiques s’accordent à dire que les informations visuelles seraient traitées 60 000 fois plus vite par le cerveau que l’information textuelle. On pourrait débattre sur la précision de ce chiffre mais on s’en rend bien compte intuitivement: une image vaut mieux qu’un long discours. De façon tout à fait équivalente, il ne fait nul doute qu’une DataViz vaut mieux qu’un long rapport.
I - Enjeux et opportunités de la DataViz
A - La DataViz c’est quoi et pourquoi ?
Pour ceux qui auraient loupé plusieurs numéros de Survey Magazine, DataViz est la contraction de deux mots : Data et Vizualization.
C’est un ensemble d’outils et de techniques de communication visuelle qui permettent de présenter clairement et efficacement de l’information. En français, on traduirait ce terme par visualisation de données et on pourrait réduire son sens aux graphiques qui les représentent.
Toutefois, à l’ère de l’information, de l’Internet des Objets (IoT) et du Big Data, ces techniques servent avant tout une philosophie : donner du sens à l’immense quantité et à l’effrayante complexité des données disponibles à travers une apparente simplicité.
B- Des études de marché nourries par une data survitaminée
Dans notre secteur, nous parlons depuis toujours de quanti et de quali, séparant ainsi en deux la recherche que nous faisons pour nos clients. Souvent, les études qualitatives servent de préambule aux études quantitatives qui ont toujours été le fer de lance des études de marché. Nous les appelons ainsi car elles permettent de quantifier statistiquement le comportement ou l’opinion des consommateurs et ainsi de généraliser les insights qu’on en extrait afin de prendre des décisions.
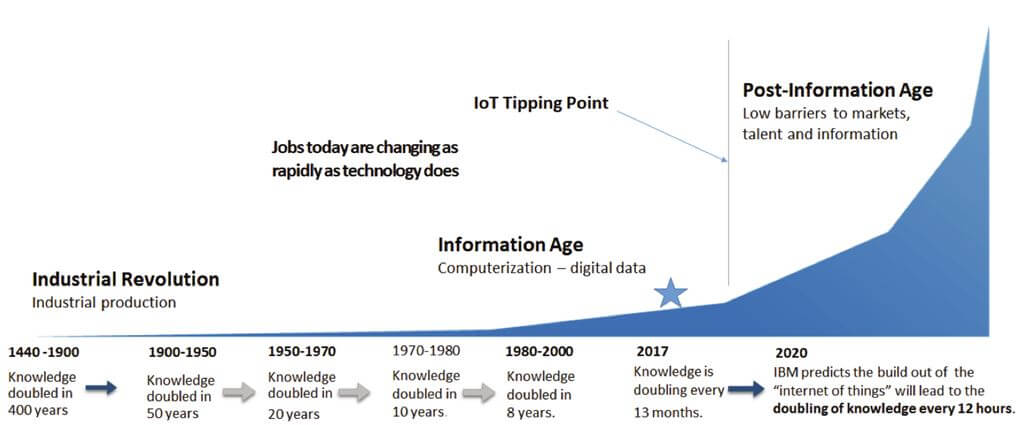
Source : Site de l’American Society for Microbiology (asm.org)
Buckminster Fuller, architecte, inventeur et futuriste américain, avait noté que jusqu’au début du 20ème siècle, la connaissance doublait approximativement tous les siècles. A la fin de la 2de guerre mondiale, il ne fallait plus qu’un quart de ce temps pour doubler la quantité de connaissance créée par l’homme. Pour 2020, soit l’an prochain, IBM prédit que nous aurons atteint le rythme de croissance doublée toutes les 12 heures ! Ne vous y trompez pas, quand IBM parle de connaissance c’est bien de données qu’il s’agit, de zettabytes (1021) de data aussi considérable que variée et complexe.

Comme si ce n’était pas suffisant, ces données et ces connaissances ont une espérance de vie bien plus courte qu’auparavant. Elles doivent être exploitées plus vite, au risque de devenir obsolètes.
En tant que professionnels des études de marché, nous ne sommes évidemment pas les plus grands producteurs de data au monde, loin de là. Toutefois nous n’en restons pas moins des producteurs de data quelle que soit notre méthode de collecte. Par ailleurs, les données que créons à travers nos études de marché et sondages ne sont pas vraiment comparables à toutes les données que l'on peut voir dans le visuel plus haut. Lorsqu’un géant du web comme Facebook ou Google collecte des données, il le fait en transparence pour le “sondé”, dans le sens où ce dernier n’a pas à répondre à un questionnaire quelconque, ces données comportementales sont un peu une mesure de la réalité.
Ainsi une analyse des tendances Google Trends peut dévoiler des réalités tout à fait surprenantes car la personne qui effectue une recherche sur Google va livrer à ce moteur des choses qu’il ne livrerait à aucun être humain. Nos instruments de collecte, en particulier le sondage qui est déclaratif, sont plus souvent le reflet d’une opinion que d’un comportement. Nous devons évidemment apprendre à exploiter toutes ces données que nous ne produisons pas mais là n’est pas la question. Là où les géants de la data puisent leurs insights dans la quantité, notre rôle va tendre vers l’analyse-agrégante. C’est là que les outils de DataViz qui permettent de se connecter à plusieurs sources de données différentes prennent tout leur sens.
C - L’autonomisation du client-expert via la data en self-service
Nous sommes peut-être experts en analyse, mais nous ne sommes généralement experts dans aucun des métiers de nos clients et nous n’avons probablement pas vocation à l’être ni à le devenir. Lorsqu’un client se présente à nous, son besoin est généralement de prendre une ou plusieurs décisions stratégiques pour son entreprise. Notre rôle d’analyste-agrégant va être de lui fournir toutes les informations nécessaires afin que cette prise de décision soit juste ou du moins la plus juste possible.
Pour une enquête de satisfaction, il s’agira de décider des actions à entreprendre pour l’améliorer. S’il souhaite étudier la taille d’un marché et ses tendances, ce sera peut-être pour prendre les bonnes décisions en termes d’investissements. Pour un nouveau concept, il pourrait s’agir de décider du lancement d’un produit voire même de la création d’une entreprise, et ainsi de suite. La data est son besoin mais c’est la prise de décision qui reste l’objectif. Une bonne prise de décision nécessite une expertise métier, raison pour laquelle nous n’avons pas d’autre choix que de travailler avec des experts lorsqu’il s’agit d’un secteur particulier et parfois même pour la collecte de données !
En tant qu’experts, l’objectif de notre travail a toujours été de faciliter cette prise de décision. Cela passe avant tout par l’apport de données fiables qui permettent d’écarter, au mieux, les effets du hasard. Cela passe également par une autonomisation du client sur les aspects d’exploration et d’analyse de données. Sur cet aspect, nous avons aussi un rôle de formation et de facilitation qui débute idéalement lors de la présentation des résultats. C’est le moment idéal pour démontrer les atouts de la DataViz et de la data en self-service. A terme, cela permet également de décharger nos équipes, en particulier les chargés d’études, sur des aller-retours inutiles avec les clients.
Aujourd’hui, le déluge de données est là, et la DataViz est certainement l’un des instruments-clé qui peut servir de rempart à la confusion. Comment ? En mettant l’incommensurable quantité de data disponible à la portée de nos capacités cognitives d’être humain. Pour nous, c’est aussi l’occasion de mettre nos outils et indicateurs statistiques à la portée des clients et donc d’une analyse-métier synergique nouvelle génération.
II - Construire la DataViz des sondages
Quand on dit DataViz, on pense d’abord à la bonne utilisation des éléments graphiques qui les composent, c’est évident. Car oui, dans Data Visualization il y a le mot visualisation. C’est vrai, il existe des graphes plus adaptés à certains types de données. Nous le savons depuis longtemps, cependant la philosophie de la DataViz nous rappelle à l’ordre. C’est pourquoi un léger rafraîchissement de nos connaissances à ce sujet s’impose tout de même.
A - Encoder les données pour optimiser leur perception
Le principe est simple, une bonne DataViz doit permettre de “lire” les
données de façon juste, précise et rapide. Pour cela, il faut
s'intéresser à la façon dont nous percevons les différentes composantes
visuelles afin de les utiliser au mieux pour transmettre l’information
derrière les données. Comme nous le verrons, plusieurs paramètres seront
à prendre en considérer :
- le type de question : dichotomiques,
choix multiples, échelle likert, etc ;
- le type de modalités et donc
de données : quantitative discrète, quantitative continue, qualitative
nominales ou qualitative ordinales ;
- le nombre de modalités ;
-
les écarts entre les données et ordres de grandeur ;
- ce que
l’on veut montrer : comparaison, distribution, (dé)composition,
relation, tendance, évolution, etc.
1 - Old but Gold: positions, longueurs, surfaces et angles
C’est en 1967 que paraît la première édition du livre: Sémiologie graphique. Les diagrammes, les réseaux, les cartes de Jacques Bertin. Cet ouvrage reste une référence dans le domaine, ce sont un peu tous les concepts utilisés dans la DataViz avant l’heure.

Les variables visuelles de Jacques Bertin: Taille, Valeur, Grain, Couleur, Orientation et Forme.
Un peu plus tard en 1986, Jock MacKinley publie une autre référence qui vient enrichir les travaux de Bertin sur les aspects de perception cognitive de cet encodage visuel.
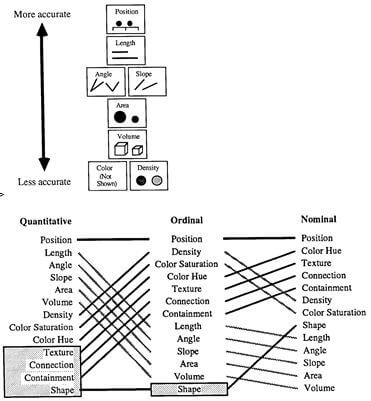
Automating the Design of Graphical Presentations of Relational Information.
2 - Précisions sur le choix des couleurs
Si on trouve déjà les couleurs dans les travaux de Bertin et de
MacKinley, leur rôle particulier nécessite quelques précisions. Il y a
trois grandes façons d’utiliser les couleurs pour faire parler les
données dans une DataViz :
- Nuancer avec un dégradé de couleurs
similaires,
- Contraster avec des teintes de couleurs très
différentes voir opposées,
- Contextualiser en reflétant la réalité
pour catégoriser.
Concernant la contextualisation, elle peut souvent être utilisées conjointement avec les nuances ou le contraste. Par exemple, pour une simple question dichotomique avec « Oui » et « Non » comme modalités, on pourra contextualiser en partie le « Non » par un rouge et le « Oui » par un vert tout en utilisant deux couleurs pratiquement opposées sur la roue chromatique.
3 - Raconter l’histoire en images et en graphiques
Afin que les données nous parlent et nous marquent, elles doivent être simples mais aussi raconter une histoire. Sans réellement parler d’encodage de la donnée par l’image, on peut parler d’un usage qui sert la contextualisation. Certaines infographies en usent abondamment mais pour une DataViz, il faut savoir les employer avec parcimonie afin qu’elles ne volent pas la vedette à la data. Ces éléments de storytelling font partie intégrante de la réalisation d’une DataViz mais choisir son histoire peut aussi être utile lors de la sélection du bon graphique.
En tant que spécialistes de la data et de sa manipulation, nous savons intuitivement quels graphiques utiliser selon les données et ce que nous voulons en faire ressortir. La DataViz ne change pas grand-chose aux choix que nous faisions précédemment si ce n’est que sa philosophie nous suggère d’y être plus sensibles.
Pour choisir la représentation graphique idéale des données, la question à se poser est : qu’est-ce que l’on veut mettre en valeur dans les données. La réponse à cette question peut être : une comparaison, une tendance, une distribution, une hiérarchie, une évolution temporelle et ainsi de suite. Un bon point de départ pour amorcer la réflexion sur le type de graphique est le brillant Chart Chooser créé par le site Extreme Presentation.
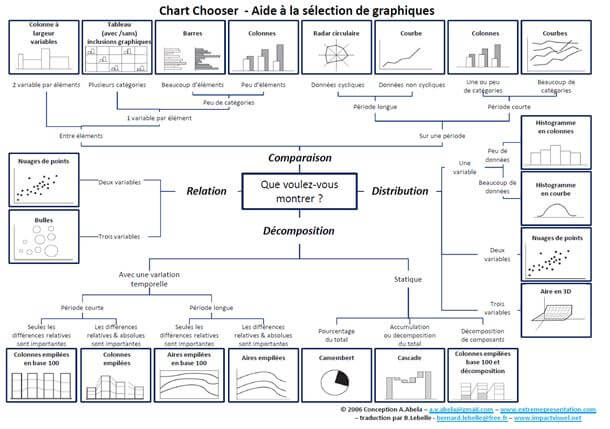
La question centrale est ici « Que voulez-vous montrer? », autrement dit, quel est le message à transmettre, quelle est l’histoire que vous voulez raconter. Cette dimension storytelling sera toujours présente dans la DataViz. Cependant, pour un sondage, la première question que l’on se posera sera tout simplement : « Quel est le type de question qui a été posé? ». Car oui, le type de question et donc de modalités influent sur tous les éléments qui permettent d’encoder efficacement les données.
À partir du type de question et de l’ensembles des informations compilées sur l’encodage visuel, on peut en déduire le tableau récapitulatif suivant :
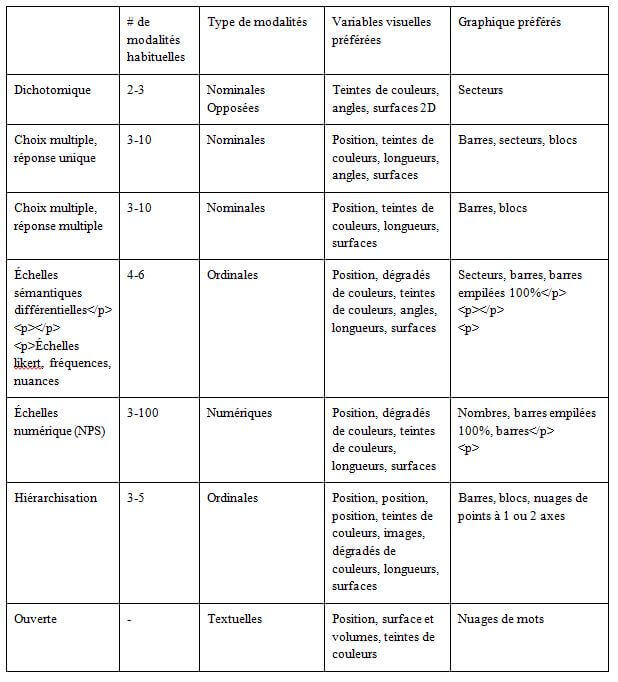
On pourrait s’arrêter là, mais entrons davantage dans les détails avec des exemples concrets accompagnés des choix visuels expliqués pour ces questions de sondage simples.
B - Choisir un graphique pour une question simple de sondage
Il existe un très grand nombre de types de questions dans un sondage et une quantité infinie de graphiques et de visuels pour les représenter. Le récapitulatif ci-dessous ne se veut en aucun cas exhaustif ni même figé. Toutefois, c’est une façon comme une autre de démarrer sa réflexion, une forme de thought starter pour la visualisation des données de sondages. Dans le doute, il n’est pas nécessaire d’aller chercher plus compliqué. D’ailleurs, dans une DataViz interactive, les données varient, il vaut donc mieux sélectionner un graphique qui supporte bien les écarts et variations. Voici donc notre thought starter pour visualiser les résultats d’une question de sondage.
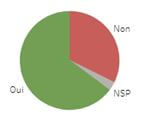
1 - Questions dichotomiques (QD)
Les questions dichotomiques ont la particularité d’avoir deux modalités généralement opposées. Quels que soient les résultats, il y a rarement mieux qu’un bon vieux camembert pour les visualiser.
Pour les couleurs, optez pour des choix qui reflètent les modalités tout en créant suffisamment de contraste pour les distinguer clairement.
Exemple de question : Utilisez-vous Facebook ?
Modalités : Oui /
Non / NSP
2 - Questions à choix multiples et à réponse unique (QCRU)
Ces questions ont des modalités qui sont généralement nominales. On en compte généralement entre 3 et 6 ce qui rend l’utilisation des graphiques ci-contre assez pratique.
Entre un camembert un graphique en barres, il est intéressant de noter si l’écart entre les données est faible, on préférera le graphique en barres qui permettra de mieux apprécier ces différences.
Si l’écart entre les données est très grand, on préférera alors les blocs de proportions qui permettent de mieux juger l’ordre de grandeur. À l’inverse, on les évitera lorsque les proportions sont proches comme dans l’exemple ci-contre.
Au vu de l’importance de la position dans la perception, lorsqu’une utilise un graphique en barre, il vaut mieux l’ordonner de façon croissante.
Enfin, il peut être intéressant de choisir le camembert lorsqu’on représente les parts d’un marché oligopolistique ou plus généralement lorsqu’on veut montrer que toutes les réponses sont une partie (pourcentage) d’un tout (100%).
Exemple de question : Si un petit équipement public de proximité
devait ouvrir demain près de chez vous, parmi les suivants lequel
serait le mieux adapté à vos besoin ?
Parcs / Éléments sportifs /
Jeux pour enfants / Jeux pour senior

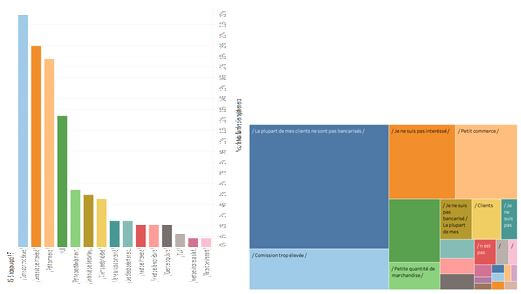
3 - Questions à choix multiples et à réponses multiples (QCRM)
Très similaires aux QCRU, ces questions ont aussi souvent des modalités nominales qu’on compte entre 3 et 6. La seule différence, toutefois importante, avec le type QCRU c’est que l’ensemble des réponses ne représente pas un tout. Certains répondant pourront opter pour 4 réponses et d’autres pour une 1 seule. Ce qui fait que la somme totale des réponses est biaisées par le nombre de choix faits par chaque participant. Par conséquent, un camembert présentera rarement de l’intérêt pour ces questions. On choisira plutôt les barres ou les blocs selon les écarts entre les résultats. S’ils sont grands, on préfèrera les blocs et s’ils sont petits, les barres pour plus de précision.
Exemple : Pour quelles raisons ne souhaitez-vous pas installer un TPE dans votre commerce?
4 - Questions à échelles sémantiques différentielles (QESD)
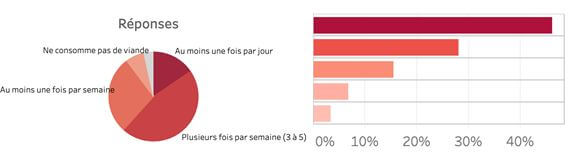
Ce type de question inclut les échelles likert. On y retrouve en général 4 à 7 modalités ordonnées, c’est pourquoi l’utilisation d’un dégradé de couleur est souvent très parlant. Quand il s’agit de fréquence par exemple, on peut choisir un dégradé de couleur et le contextualiser pour le choix de la couleur principale. En ce qui concerne le type de graphique, les barres et les barres empilées 100% fonctionnent plutôt bien pour ce type de questions.
Exemple : À quelle fréquence diriez-vous que vous consommez de la
viande?
Au moins une fois par jour / Plusieurs fois par semaines
/ Au moins 1 fois par semaine / Moins souvent / Ne consomme pas de
viande
Exemple de question : À propos de la phrase suivante : “La musique est un élément important dans ma vie”. Diriez-vous que vous êtes …? Pas d’accord / Plutôt pas d’accord / Plutôt d’accord / D’accord
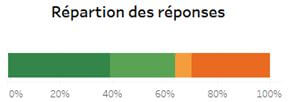
Lorsque les extrêmes de l’échelles s’opposent, par exemple pour une échelle likert, on peut utiliser des dégradés de couleur divergentes comme dans le visuel ci-dessus.
5 - Questions à échelles numériques (QEN)
Pour une simple question numérique, une bonne façon de visualiser les résultats c’est parfois simplement d’afficher des chiffres. On utilisera au besoin les calculs statistiques simples comme la somme, la moyenne ou encore la médiane. Les chiffres eux-mêmes attirent beaucoup l’attention. Par conséquent, il vaut mieux en choisir peu et les choisir bien. S’il y’en a trop, ils rendront la DataViz confuse.
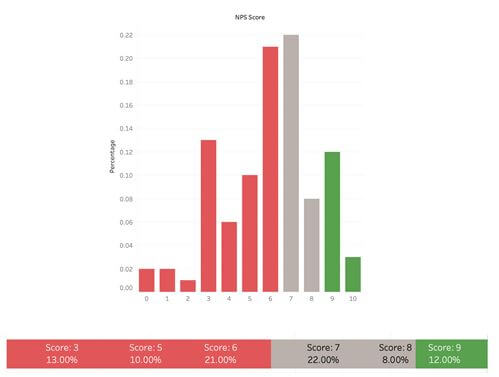
Pour un NPS (Net Promoter Score) ou même pour d’autres scores que l’on veut catégoriser, on pourra utiliser les astuces des échelles sémantiques en profitant de la classification Détracteurs / Passifs / Promoteurs.
Exemple de question : Sur une échelle de 0 à 10, quelle est la probabilité que vous recommandiez telle marque ou tel produit à un ami ou un collègue ?
6 - Questions de hiérarchisation (QH)
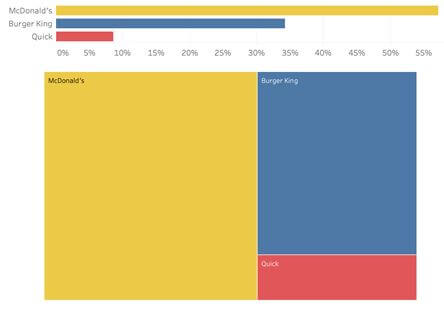
Pour ces questions, on demande au répondant de hiérarchiser plusieurs éléments selon un critère. Les données sont ordonnées mais ont souvent un caractère nominal.
On encodera l’aspect nominal avec des teintes de couleurs différentes et l’aspect ordonné avec un graphique en bar par exemple, en prenant soin d’afficher en premier l’élément le plus important.
On pourra aussi utiliser un graphique plus classique à deux axes en gardant à l’esprit que lorsqu’il s’agit de hiérarchisation, c’est la position la plus élevée qui sera immédiatement perçue comme la plus importante.
Exemple de question : Classez ces 3 Fast Food par ordre de préférence. Burger King / McDonald's / Quick
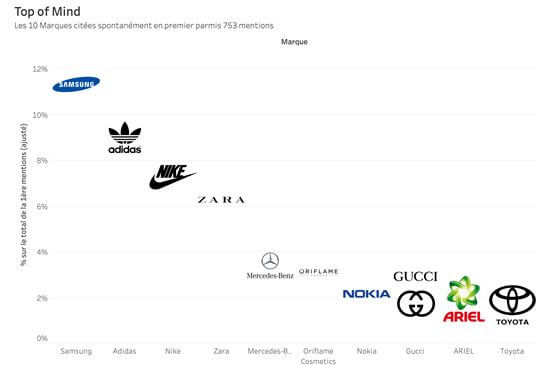
Exemple de question : Citez les 3 premières marques qui vous viennent à l’esprit.
7 - Questions ouvertes (QO)
Les questions ouvertes ont une spécificité par rapport aux précédentes : elle sont 100% textuelles. L’analyse d’une question ouverte n’est pas une chose aisée que l’on peut visualiser simplement sans prendre le temps d’en saisir la substance. Il existe maintenant des outils qui permettent l’analyse avancées de l’intention. Cependant, une façon simple de visualiser le contenu d’une question ouverte sans en analyser le sens qui s’y trouve, c’est l’utilisation d’un nuage de mots comme celui qui se trouve ici.

L’exemple de nuage de mots ci-dessus est basé sur une version de l’article que vous lisez.
Notons que tous ces choix conviennent aux résultats d’une question simple. Cependant, lorsqu’il s’agit de croiser les données entre questions ou d’ajouter un composante temporelle ou cartographique, les choix seront évidemment différents bien que les principes utilisés resteront applicables. On utilisera alors d’autres types graphiques : les courbes pour montrer une évolution, les nuages de points pour une tendance ou encore une carte pour des données géographique.
Pour finir, notons également que tous ces éléments s’appliquent entièrement aux infographies. Ces dernières ont aussi beaucoup d’intérêt pour communiquer des données complexes visuellement. Mais alors, quelle différence avec la DataViz ? La différence c’est l'interactivité, et c’est là que la donne est bouleversée.
C- Explorer, ludifier et impliquer avec l’interactivité
Dans le mot DataViz rien ne l’évoque et pourtant, c’est une de ses composantes principales : il s’agit de l'interactivité. Sans cette dernière, nous n’aurions jamais inventé un nouveau concept pour faire des graphiques avec une nouvelle philosophie. C’est d’ailleurs cette interactivité qui est ouvre les portes des nouvelles opportunités offertes par la DataViz. Elle offre les possibilités infinies d’une nouvelle dimension : l’exploration des données et leur manipulation par le consommateur final de la donnée.
Lorsqu’on construit une visualisation de donnée, il est impérativement nécessaire d’adopter un mindset orienté interactivité. Vous vous en rendrez rapidement compte, cet article lui-même aurait probablement gagné à être davantage interactif.
1 - Explorer sans limite mais dans la simplicité
Pourquoi avoir plusieurs graphiques pour les différents croisements démographiques quand on peut tout avoir dans un seul visuel ? Il suffit ensuite d’ajouter des filtres autour pour permettre de limiter les résultats à une région géographique et/ou à une tranche d’âge. Une DataViz bien pensée peut permettre d’accéder une immense quantité de data à travers des éléments visuels simples.
Néanmoins, attention à ne pas se perdre, la simplicité reste de mise. L'interactivité doit apporter puissance et ludification (gamification) mais pas complexité. Pour cela on peut utiliser les techniques du dashboarding, c’est à dire organiser l’information comme on présenterait les KPI à un décideur, le tout sur un seul écran afin que l’utilisateur final puisse en un clin d’œil avoir une vue générale de l’information. De façon générale, une bonne DataViz intéractive doit apporter des réponses dans sa vue d’ensemble. L'interactivité peut être utilisée pour approfondir mais elle ne doit pas rendre confuse l’information présentée.
Les filtres peuvent évidemment prendre la forme de listes déroulantes, de boutons radio et autres boîtes à cocher mais on pourra aussi faire preuve de plus d’imagination. Voici un exemple tiré de l’une de nos DataViz :
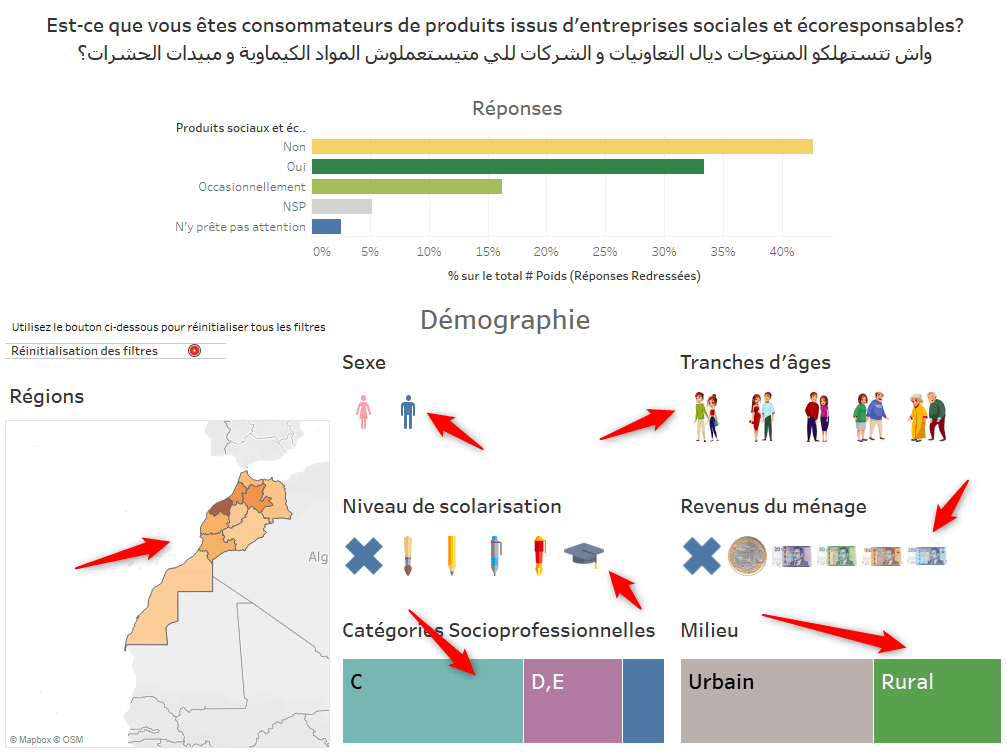
Chaque élément graphique pointé par une flèche rouge devient un filtre. Après 3 simples clics, les résultats ne représentent plus que les femmes urbaines âgées de 25 à 34 ans. L’utilisation d’images peut faciliter la contextualisation, servir la compréhension et rendre l’exploration des résultats plus ludique.
2 - Rendre accessible la statistique
Une autre opportunité offerte par la DataViz est l’accès aux outils statistiques et surtout leur simplification. Ainsi, n’importe quel néophyte peut utiliser et exploiter la puissance analytique et prédictive offerte par la statistique. On peut évidemment utiliser les classiques moyennes, médianes et écarts types avec des lignes de référence ou des boîtes à moustache, ce qui permet déjà de faire beaucoup, mais on peut aussi aller plus loin.
Avec l’aide de l'interactivité et d’un peu d’imagination, on peut permettre au client de trouver lui-même des corrélations entre les données en calculant par exemple à la volée les coefficients de Pearson. En modifiant les données à la volée, il devient aussi possible de comparer rapidement les tendances dégagées par des calculs de régression linéaire ou multiples.
Dans le cadre d’un sondage, un exemple simple et intéressant est l’affichage dynamique de la marge d’erreur selon la taille variante de l’échantillon. Ainsi, l’utilisateur final conserve une estimation de la justesse de son information tout au long de l’exploration.
Si on reprend l’exemple de DataViz précédent en y ajoutant la marge d’erreur, on a :
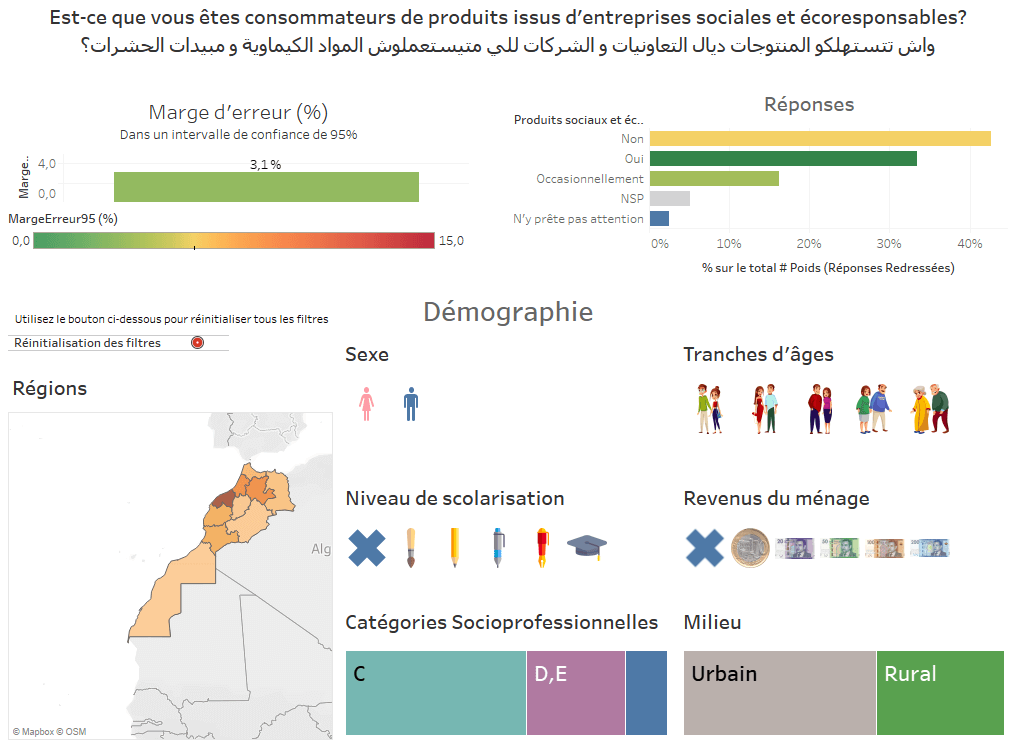
Ainsi, en filtrant les résultats sur les 25-34 ans qui ont un niveau d’éducation supérieur en deux clics, on peut garder un œil sur une estimation à la volée de la marge d’erreur.
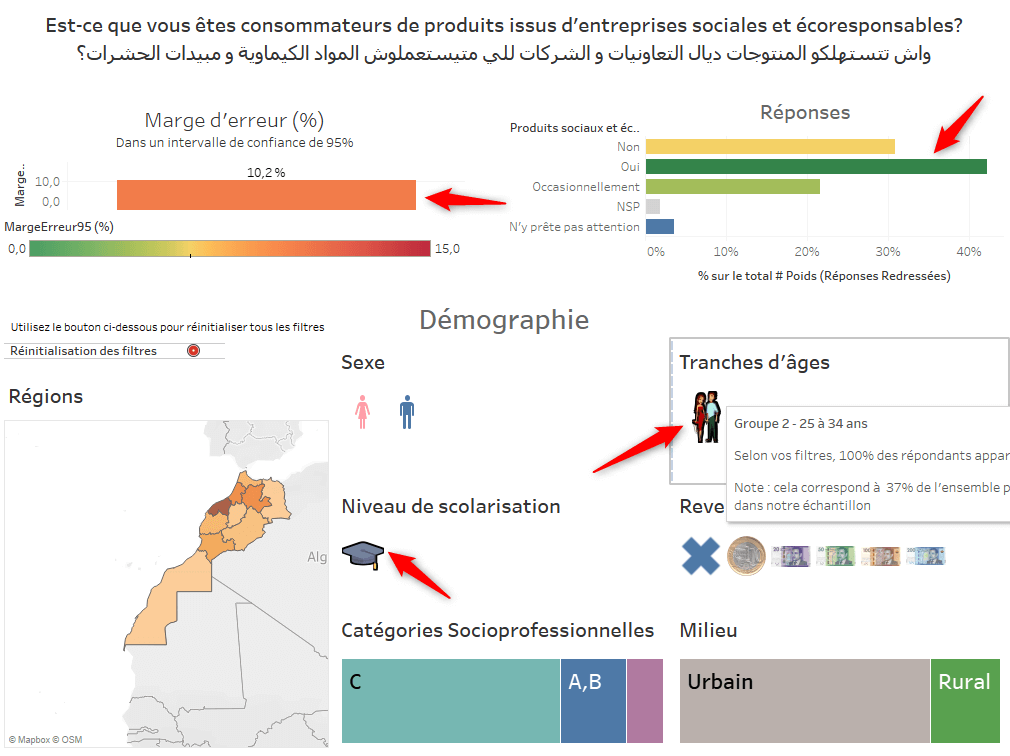
L’utilisateur de la DataViz peut savoir en temps réel si les résultats qui s’affichent présentent des différences significatives ou non. Ceci est un bon exemple de comment on peut autonomiser le client sur l’exploration juste de ses données tout en rendant le processus plus amusant et plus ludique
Il convient de rappeler que la statistique n’est pas une science exacte. Au vu des récentes innovations dans l’analyse de données, il y a de fortes chances pour qu’elle évolue significativement dans les années à venir.
Pour finir, il ne faut pas hésiter à faire preuve d’imagination en combinant des graphique et des images voire en inventant de nouvelles façons de visualiser les données. Il y a encore bien de la place pour l’innovation et la créativité. On connaît déjà les visualisations de données qui prennent la forme de vidéos comme ces fameux classements de capitalisations boursières en barres qu’on voir évoluer au fil du temps.
Cependant, le futur [proche] nous amènera certainement à des exploration de données encore plus surprenantes. En utilisant des outils comme la réalité virtuelle par exemple, façon Minority Report de Steven Spielberg, repoussant ainsi le concept de data you can touch à son paroxysme.
III - Des considérations éthiques renouvelées
Lorsqu’on met en valeur certaines données consciemment, c’est dans le but de faciliter le travail du client. Il est l’expert dans son métier, c’est lui qui doit prendre les décisions qui découlent de nos études. Pourtant, nous sommes responsables de ces données et c’est encore davantage le cas quand il s’agit de DataViz qui est une forme très abrégée des résultats de nos travaux.
Si la DataViz permet d’y voir plus clair dans le déluge de données, c’est aussi parce qu’on omet volontairement une partie des données ou du moins qu’on met en valeur une partie plutôt qu’une autre. En tant que professionnels des études de marché, de l’analyse de donnée et de la statistique, nous somme les plus à même de faire ce tri. Afin que des données insignifiantes ne soit pas mal exploitées, nous nous devons d’être transparents et clairs sur la significativité des données que nous présentons.
Nous devons combattre davantage toutes les formes de biais cognitifs. Il faut par exemple maîtriser les échelles des graphiques et garder les mêmes lorsqu’on compare plusieurs variables. Nous devons aussi réfléchir à nos choix de teintes ou dégradés de couleurs afin qu’ils reflètent les données de façon adéquate. Nous devons aussi contrôler les effets de l'interactivité, surtout dans les cas extrêmes pour éviter de dépeindre des situations trop exagérées. Enfin, il ne faut jamais oublier l’audience à laquelle nous présentons nos résultats car l’interprétation des couleurs et des formes peut parfois changer drastiquement d’une culture à une autre.
Nous avons alors un rôle pédagogique vis à vis de nos clients sur ces nouvelles technologies. Quand la DataViz est bien exploitée, notre client autonome est habilité à explorer lui-même les données pour en tirer les insights nécessaires. Ses conclusions peuvent ensuite être présentées à de nombreuses autres personnes, toutes influencées par les choix que nous avons fait en amont.
Quand on raconte une histoire à travers une DataViz ou même une infographie, il faut souvent introduire une narration, des éléments perturbateurs et des péripéties. C’est ainsi que l’on peut transformer une data un peu ennuyeuse en une histoire intéressante voire passionnante. C’est ensuite à nous de savoir rester neutres et d’essayer autant que possible de ne pas faire basculer nos histoires vers des schémas trop manichéens. Ce que l’on choisit de dire ou de montrer à travers une DataViz est finalement le résultat de nos croyances. Ce n’est qu’en étant conscient de ces aspects que l’on peut les contrôler et assumer les responsabilités éthiques intrinsèques à notre métier et à la DataViz.










